Abstract
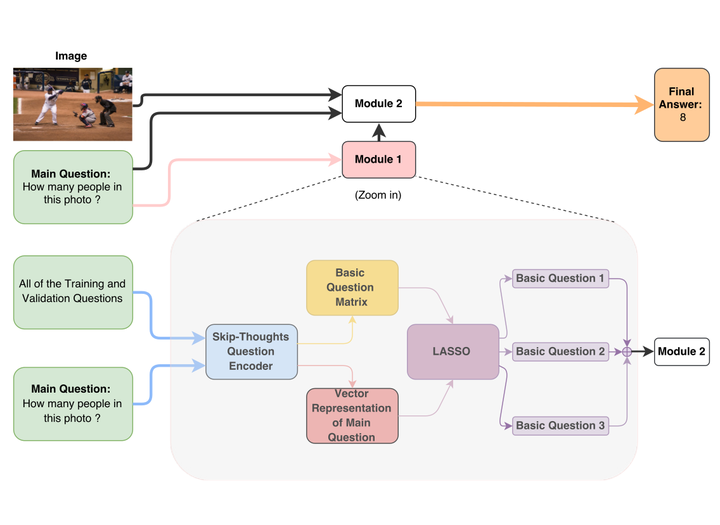
Taking an image and question as the input of our method, it can output the text-based answer of the query question about the given image, so called Visual Question Answering (VQA). There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the basic questions of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question. We formulate the basic questions generation problem as a LASSO optimization problem, and also propose a criterion about how to exploit these basic questions to help answer main question. Our method is evaluated on the challenging VQA dataset and yields state-of-the-art accuracy, 60.34% in open-ended task.
This paper was accepted to the 2nd VQA workshop in CVPR17 [source]