Abstract
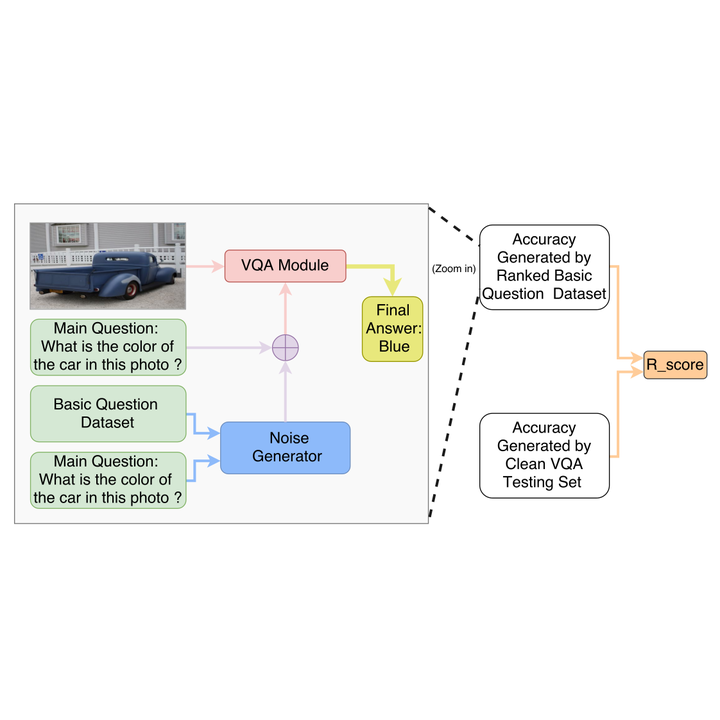
Visual Question Answering (VQA) models should have both high robustness and accuracy. Unfortunately, most of the current VQA research only focuses on accuracy because there is a lack of proper methods to measure the robustness of VQA models. There are two main modules in our algorithm. Given a natural language question about an image, the first module takes the question as input and then outputs the ranked basic questions, with similarity scores, of the main given question. The second module takes the main question, image and these basic questions as input and then outputs the text-based answer of the main question about the given image. We claim that a robust VQA model is one, whose performance is not changed much when related basic questions as also made available to it as input. We formulate the basic questions generation problem as a LASSO optimization, and also propose a large scale Basic Question Dataset (BQD) and Rscore (novel robustness measure), for analyzing the robustness of VQA models. We hope our BQD will be used as a benchmark for to evaluate the robustness of VQA models, so as to help the community build more robust and accurate VQA models.
This paper was accepted to the Visual Dialog Workshop in CVPR18 [source]